
来自: link
大概是我看过最简单易懂的一篇…有空的时候会在这里做一下翻译.
!!已经更新翻译!!
环境
假设我们有5个相互连接的房间, 并且对每个房间编号, 整个房间的外部视作房间5.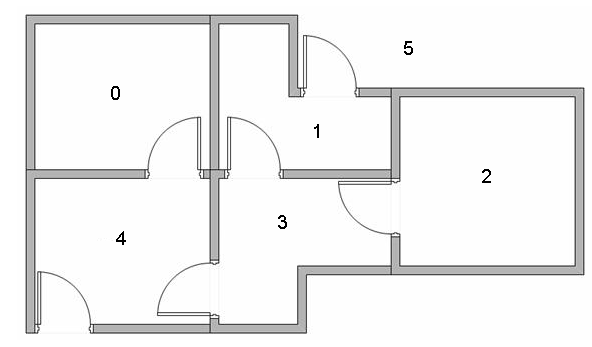
以房间为节点, 房门为边, 则可以用图来描述房间之间的关系: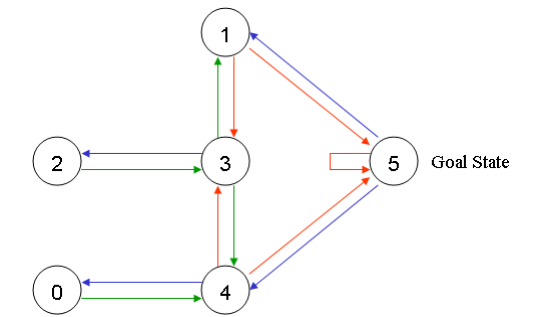
奖励机制
这里设置一个agent(在强化学习中, agent意味着与环境交互、做出决策的智能体), 初始可以放置在任意一个房间, agent最终的目标是走到房间5(外部).
为此, 为每扇门设置一个reward(奖励), 一旦agent通过该门, 就能获得奖励: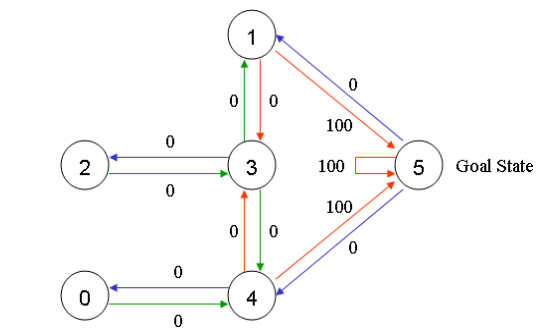
其中一个特别的地方是房间5可以循环回到自身节点, 并且同样有100点奖励.
在Q-learning中, agent的目标是达成最高的奖励值, 如果agent到达目标, 就会一直停留在原地, 这称之为absorbing goal.
对于agent, 这是i一个可以通过经验进行学习的robot, agent可以从一个房间(节点)通过门(边)通往另一个房间(节点), 但是它不知道门会连接到哪个房间, 更不知道哪扇门能进入房间5(外部).
学习过程
举个栗子, 现在我们在房间2设置一个agent, 我们想让它学习如何走能走向房间5.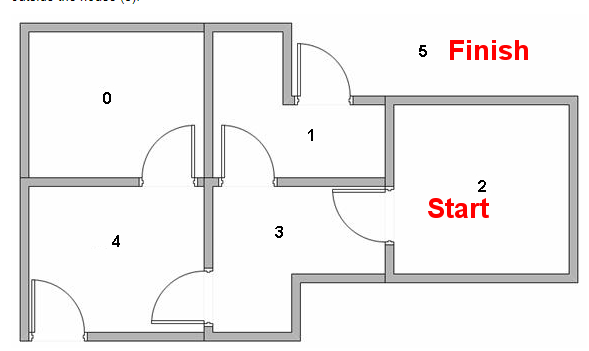
在Q-leanring中,有两个术语state(状态)和action(行为).
每个房间可以称之为state, 而通过门进行移动的行为称之为action, 在图中state代表节点, action代表边.
现在代理处于state2(节点2, 房间2), 从state2可以通往state3, 但是无法直接通往state1.
在state3, 可以移动到state1或回到state2.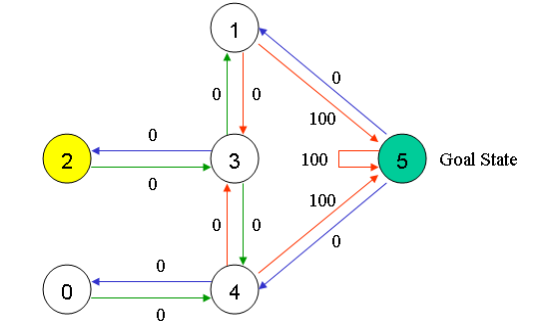
根据现在掌握的state, reward, 可以形成一张reward table(奖励表), 称之为矩阵R: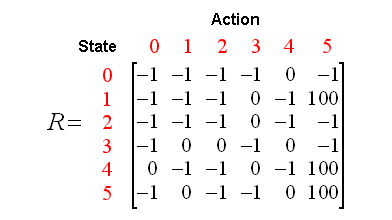
只有矩阵R是不够的, agent还需要一张表, 被称之为矩阵Q, 矩阵Q表示agent通过经验学习到的记忆(可以理解为矩阵Q就是模型通过学习得到的权重).
起初, 代理对环境一无所知, 因此矩阵Q初始化为0. 为了简单起见, 假设状态数已知为6. 如果状态数未知, 则Q仅初始化为单个元素0, 每当发现新的状态就在矩阵中添加跟多的行列.
Q-learning的状态转移公式如下:
根据该公式, 可以对矩阵Q中的特定元素赋值.
agent在没有老师的情况下通过经验进行学习(无监督), 从一个状态探索到另一个状态, 直到到达目标为止. 每次完整的学习称之为(episode, 其实也就相当于epoch), 每个episode包括从初始状态移动到目标状态的过程, 一旦到达目标状态就可以进入下一个episode.
算法过程
- 设置gamme参数, 在矩阵R中设置reward.
- 初始化矩阵Q.
- 对于每一个episode:
选择随机的初始状态(随便放到一个房间里).
如果目标状态没有达成, 则
- 从当前所有可能的action中选择一个.
- 执行action, 并准备进入下一个state.
- 根据action得到reward.
- 计算$Q(state, action) = R(state, action) + Gamma * Max[Q(next-state, all actions)]$
- 将下一个state设置为当前的state.
- 进入下一个state.
- 结束.
在算法中, 训练agent在每一个episode中探索环境(矩阵R), 并获得reward, 直到达到目标状态. 训练的目的是不断更新agent的矩阵Q: 每个episode都在对矩阵Q进行优化. 因此, 起初随意性的探索就会被通往目标状态的最快路径取代.
参数gamme取0到1之间. 该参数主要体现在agent对于reward的贪心程度上, 具体的说, 如果gamma为0, 那么agent仅会考虑立即能被得到的reward, 而gamma为1时, agent会放长眼光, 考虑将来的延迟奖励.
要使用矩阵Q, agent只需要查询矩阵Q中当前state具有最高Q值的action:
- 设置当前state为初始state.
- 从当前state查询具有最高Q值的action.
- 设置当前state为执行action后的state.
- 重复2,3直到当前state为目标state.
Q-learning模拟
现在假设gamme=0.8, 初始state为房间1.
初始化矩阵Q: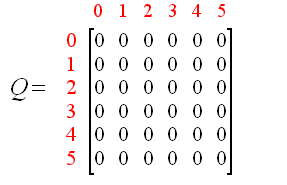
同时有矩阵R: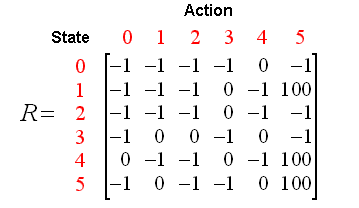
episode 1
现在agent处于房间1, 那么就检查矩阵R的第二行. agent面临两个action, 一个通往房间3, 一个通往房间5. 通过随机选择, 假设agent选择了房间5.
由于矩阵Q被初始化为0, 因此Q(5,1), Q(5, 4), Q(5, 5)都是0, 那么Q(1, 5)就是100.
现在房间5变成了当前state, 并且到达目标state, 因此这一轮episode结束.
于是agent对矩阵Q进行更新, 注意这里图是错的, 应该是Q(1, 5)=100:
episode 2
现在, 从新的随机state开始, 假设房间3为初始state.
同样地, 查看矩阵R的第四行, 有3种可能的action: 进入房间1、2或者4. 通过随机选择, 进入房间1. 计算Q值:
现在agent处于房间1, 查看矩阵R的第二行. 此时可以进入房间3或房间5, 选择去5, 计算Q值:
由于到达目标state, 对矩阵Q进行更新, Q(3, 1)=80, Q(1, 5)=100.
episode n
之后就是不断重复上面的过程, 更新Q表, 直到结束为止.
推理
假设现在Q表被更新为:
对数据标准化处理( matrix_Q / max(matrix_Q)), 可以将Q值看作概率:
描绘成图: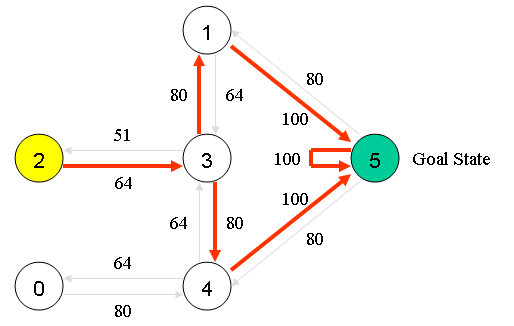
到这里已经很清晰了, agent已经总结出一条从任意房间通往房间5(外部)的路径.