
损失函数可以说是模型的指路牌, 也是深度学习中比较具有可解释性的部分, 我认为一个合适的损失函数所带来的提升是相当大的, 这里因此写一篇博客来聊一聊 optimizing directly for the metric.
>>
- 损失函数(loss function) 是机器学习的基本. 我们需要通过损失函数对训练样本的误差进行度量, 同时损失函数必须可微, 从而通过反向传播机制将梯度回传并且更新模型的权重.
- 评估函数(evaluation function)用来评估模型的性能. 这个函数必须在一定程度上反映出模型在现实世界中的表现(性能).
模型的最终目的是优化这两个函数, 而最终的性能取决于评估函数. 所以为什么不直接优化评估函数呢? 实际上目前有很多方法已经在这么做了, 并且相当好用.
1. Optimizing directly for the F1-Score in binary classification
在分类问题中, 常常以 f1-score 作为metric: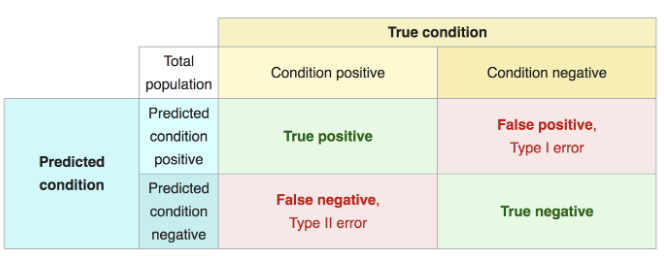
以 BCE(Binary Cross Entropy) 作为损失函数:
关于CE, 推荐一篇文章从最优化的角度看待Softmax损失函数.
通常, 模型为每个输入生成对应的概率后, 需要通过阈值(通常是0.5)将概率离散化, 从而计算f1-score. 我们以$-\log(p)$代表对观察值(输入样本)的负对数似然(log likelihood), 这样的做法很常用, 但是这似乎与f1-score没有直接的关系.
损失函数可以指导模型如何拟合我们的目标, 某种意义上, 我们也是在拟合metric(在这里是f1-score). 那么直接f1-score似乎是非常直觉的方法.
但是需要注意, 损失函数的原则是可微, 而f1-score是不可微的. 既然不可微, 那么smooth成可微的形式就可以了.
Modifiy the F1-score
步骤其实很简单, 由于FN, FP, TN, TP都是离散值, 这是导致不可微的罪魁祸首. 我们可以直接使用概率, 而不是通过阈值将概率离散化, 从而计算似然值的连续和.1
2
3
4
5
6
7def soft_f1_score(y, y_hat, eps=1e-6):
tp = (y_hat * y).sum(0)
fp = (y_hat * (1 - y)).sum(0)
fn = ((1 - y_hat) * y).sum(0)
soft_f1 = 2*tp / (2*tp + fn + fp + eps)
loss = 1 - soft_f1
return loss.mean()
一旦该损失真正起作用, 那么f1-score与loss相加会为1, 这表明模型正在直接对指标进行优化. 这样做的好处在于:
- soft f1 score实际上默认以0.5的阈值训练模型, 在现实中, 优化CE的模型往往会由于问题场景的不同而需要不同的阈值(比如某个类别数量非常少), 而soft f1 score能减少对阈值的敏感. 直观地说, 由于我们优化的是评估函数, 因此不需要搜索特定的阈值去最大化模型在验证集中的评估函数(换句话说, 输出会尽可能地接近0或1, 这也导致了对阈值的不敏感).
2. Optimizing directly for the DICE in segmentation
Dice loss
同样, 直接优化metric的方式在分割问题也相当实用.
在分割任务中, 通常以dice作为评估函数(什么是dice?). 通常, 损失函数为pixel-wise cross entropy.
DICE可以评估两个集合的相似度, 在形式上类似IOU:
在数值上, $DICE > IOU$.
显然, pixel-wise cross entropy也不能直接优化DICE, 那么与soft f1 score一样, 用概率替代离散值, 从而变得可微, 与前面所提到的思路差不多.1
2
3
4
5
6
7
8
9
10def dice_loss(pred, target):
smooth = 1.
iflat = pred.contiguous().view(-1)
tflat = target.contiguous().view(-1)
intersection = (iflat * tflat).sum()
A_sum = torch.sum(tflat * iflat)
B_sum = torch.sum(tflat * tflat)
return 1 - ((2. * intersection + smooth) / (A_sum + B_sum + smooth) )
通常, dice loss表现比ce好, 但是也有一些问题. 使用dice loss训练的模型在metric上占优, 在视觉表现上确不如ce, 这实际上是数据科学面临的一个困境, 选择实用还是选择刷分?
(我认为某种程度上能反应对于分割而言, DICE不是最好的metric)
Lovase loss
这是一个用好了很能涨点的损失, arxiv: The Lovász-Softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks
数学上的证明非常严谨且复杂, 效果也相当好, 本质上也是优化metric(针对IOU).
在个人的实践中, 这个损失比较”难用”, 在训练的初期不是非常稳定, 因此通常会搭配CE来用.
关于这个损失建议直接看paper, 这里就不多说了(因为后半段证明我也没有完全看懂, 哈哈..)
3. Optimizing directly for the IOU in object detection
在目标检测领域中, 预测框与标签框(GT)的匹配程度用IOU来表示.
一开始, 大家都用mse(Mean Squared Error)来监督预测框, 从回归得到的预测框坐标与GT计算l1 loss.
然而, mse的缺点很多(可以看看IOU loss的paper, UnitBox: An Advanced Object Detection Network):
- mse在数值上的不稳定导致损失的组合上需要对加权平均调参.
- mse对于预测框的监督实际上是非常”狭义”的. BTW, 在数值上难以反映预测框的质量.
- 往往需要对回归数值做各种预处理(exp或者归一化).
- 优化四个独立的变量,没有利用四个变量的相关性.
需要调参的损失往往比较”难用”.
由此衍生出各种基于IOU的损失: IOU、GIOU、DIOU、CIOU…
由于判断预测与GT匹配程度直接用IOU衡量, 采用IOU loss也是一件非常直觉的方法. 并且IOU有许多良好的性质, 从比较主观的视角来说, 我认为IOU loss是全方位优于mse的.
当然IOU loss也不是没有缺点, 因此陆陆续续出现了IOU loss family.
下面的代码来自https://github.com/miaoshuyu/object-detection-usages.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23def get_iou(pred_bbox, gt_bbox):
'''
:param pred_bbox: [x1, y1, x2, y2]
:param gt_bbox: [x1, y1, x2, y2]
:return: iou
'''
ixmin = max(pred_bbox[0], gt_bbox[0])
iymin = max(pred_bbox[1], gt_bbox[1])
ixmax = min(pred_bbox[2], gt_bbox[2])
iymax = min(pred_bbox[3], gt_bbox[3])
iw = np.maximum(ixmax - ixmin + 1.0, 0.)
ih = np.maximum(iymax - iymin + 1.0, 0.)
inters = iw * ih
# uni=s1+s2-inters
uni = (pred_bbox[2] - pred_bbox[0] + 1.0) * (pred_bbox[3] - pred_bbox[1] + 1.0) + \
(gt_bbox[2] - gt_bbox[0] + 1.0) * (gt_bbox[3] - gt_bbox[1] + 1.0) - inters
iou = inters / uni
return iou
Other
是否能直接优化AUC? Sure, 这还能缓解一部分数据不平衡带来的问题.
Maximizing AUC with Deep Learning for Classification of Imbalanced Mammogram Datasets
实际上还有一篇文章, 有提到Mamilton Jacobi Bellman方程来做可惜我找不到了, 以后想起出处或许会补回来.