
paper: https://arxiv.org/abs/1912.04488
code: 还没放出来这是一种one-shot instance segmentation模型, 思路是比较新颖的. 具体的说, 将实例用尺寸和位置来表示. 对于尺寸, 可以利用FPN分割不同尺寸的物体, 对于位置, 将图片划分为$s×s$个网格, 判断实例属于哪一个网格. 整体思路清晰明了, 并且模型也很容易理解.
整体来说
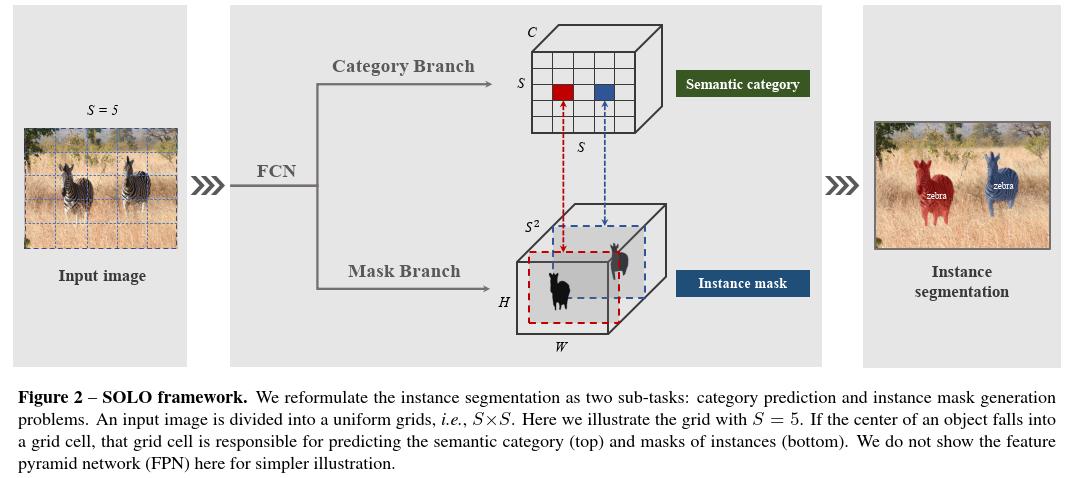
十分干净的模型, SOLO的中心思想在于把实例分割问题转变为实例分类问题, 通过将图片分为$S×S$个网格, 这是为了position sensitive.
通过category branch解决语义分类问题, 通过mask branch解决实例的位置问题.
打个比方, 如果检测到2个实例(不一定真的是2个), 但是这2个实例具有相同的位置、分类以及尺寸, 那么这2个实例就属于同一个实例.
对于尺寸, 利用FPN中的不同层来分割不同尺寸的物体.
对于位置, 利用事先划分好的$S×S$个网格, 一旦中心落入其中一个网络, 那么他的位置就是这个网格.
对于分类, 其实不是很重要, 一般而言, 两个物体尺寸和位置完全相同(或者几乎完全相同), 那么几乎可以肯定是同一个实例.
到了这里, 核心思想已经定下来了, 剩下的内容就是基于这个思路进行的各种技术上的细节优化.
比如说: 最终输出$H×W×S^2$的tensor, 这是相当大的, 于是作者提出Decoupled SOLO, 使得最终只需要输出$H×W×(S+S)$, 并且能维持原本的性能, 使得显存开销大大降低. 简单地描述, 作者直接预测x方向和y方向的mask.
其次, 考虑到position sensitive, 文章中使用coorconv(也可以 semi-convolutional, 只是coorconv比较好操作), 在分割上用的是Dice loss.
 显然, 最后需要NMS, 作者的做法是直接用Mask IOU来做.
显然, 最后需要NMS, 作者的做法是直接用Mask IOU来做.
结论
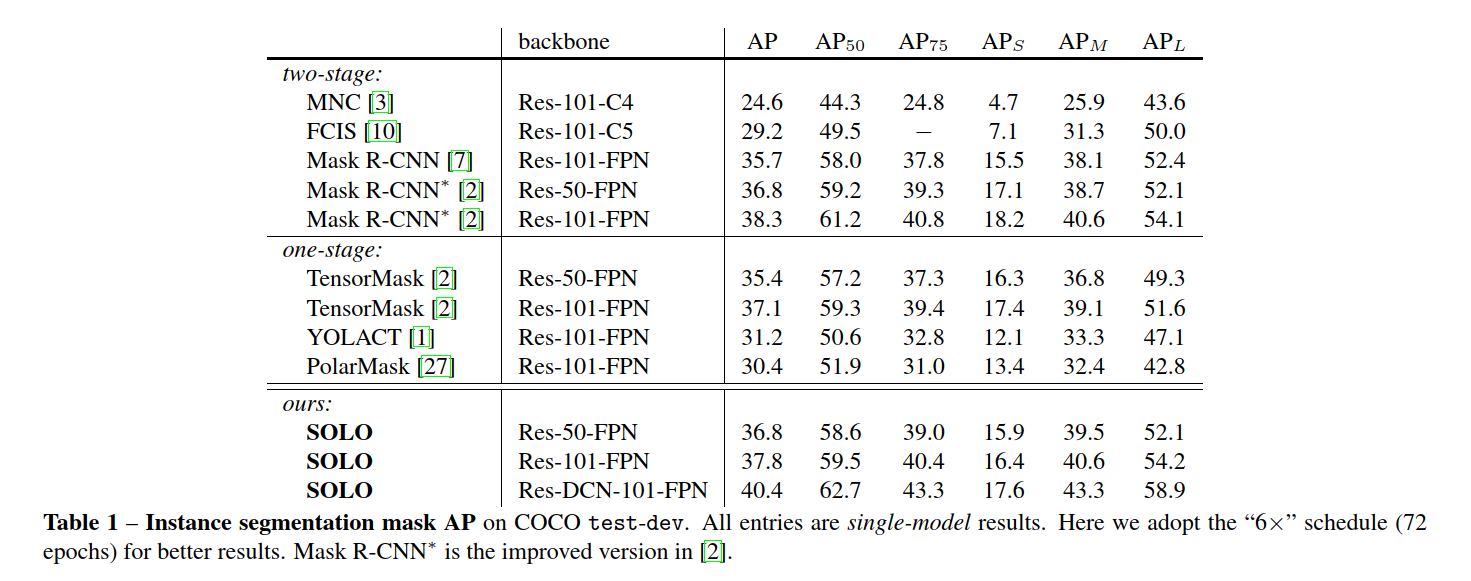
精度很好, 框架很干净. 因为源码还没有放出来, 更多的细节还不清楚.
我认为实例分割由两阶段走向单阶段几乎是必然的, 就像目标检测一样. 这篇文章有点类似于YOLO, 同样通过划分网格的方式, 并且在单阶段上实现的很好的精度, 不知道以后会不会出现如同SSD一样的实例分割框架, 又快又准~