
Google AI在上周放出来的一篇paper: Filter Response Normalization, 简称FRN, 旨在提出新的normalization layer, 同时也提出了新的激活函数TLU.
paper: https://arxiv.org/pdf/1911.09737.pdf
code: 比较简单, 自己写了一个, code.
相关工作
在这之前已经有BN、LN(Layer norm)、IN(Instance norm)和GN(Group norm), 具体都是怎么做的, 直接看这张图就够了(图片来自GN的paper):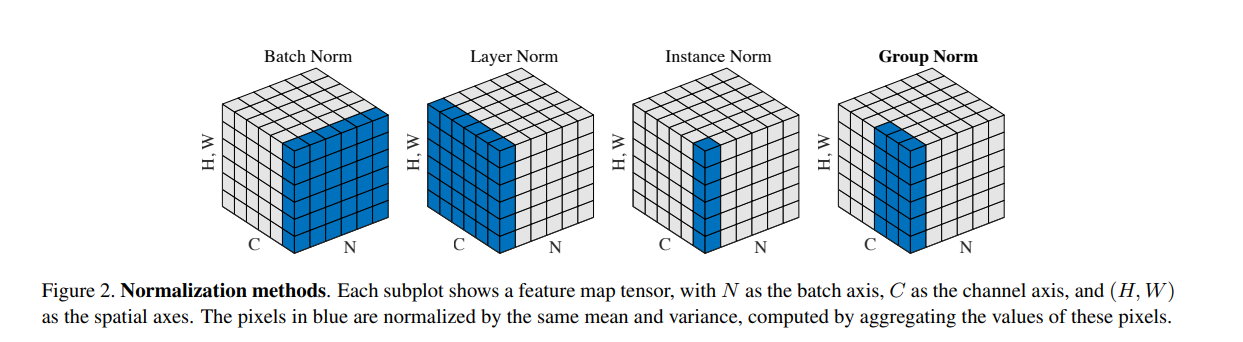
- BN从batch维度归一化, 对小batch不友好.
- LN从channel维度归一化, 主要用在RNN上.
- IN在一个channel内做归一化, 主要用在风格迁移.
- GN主要考虑将channel分为若干个group, 在group内归一化.
具体来说, 我们主要关注BN、GN和这篇文章提出的FRN.
GN旨在解决BN对小batch不友好的问题, 实验结果来看效果很好(但是我自己实际用下来感觉没那么好…).
而FRN在以一种不同于GN的方法来解决BN所存在的问题, 进一步提升了网络的性能, 并且提出了新的激活函数TLU来配合FRN使用.
FRN(Filter Response Normalization)
符号定义:
$x$代表feature map.
归一化公式:
FRN没有使用关于batch的变量, 也就不会受制于batch的大小.
并且FRN没有减去mean, 而是把mean交给TLU来处理.
需要注意的是, $\varepsilon$也是可学习的.
TLU(Thresholded Linear Unit)
这部分更简单, 提出一个可学习的参数$\tau$, 直接计算:
本质上, 就是一个可学习的ReLU…
Result
很不错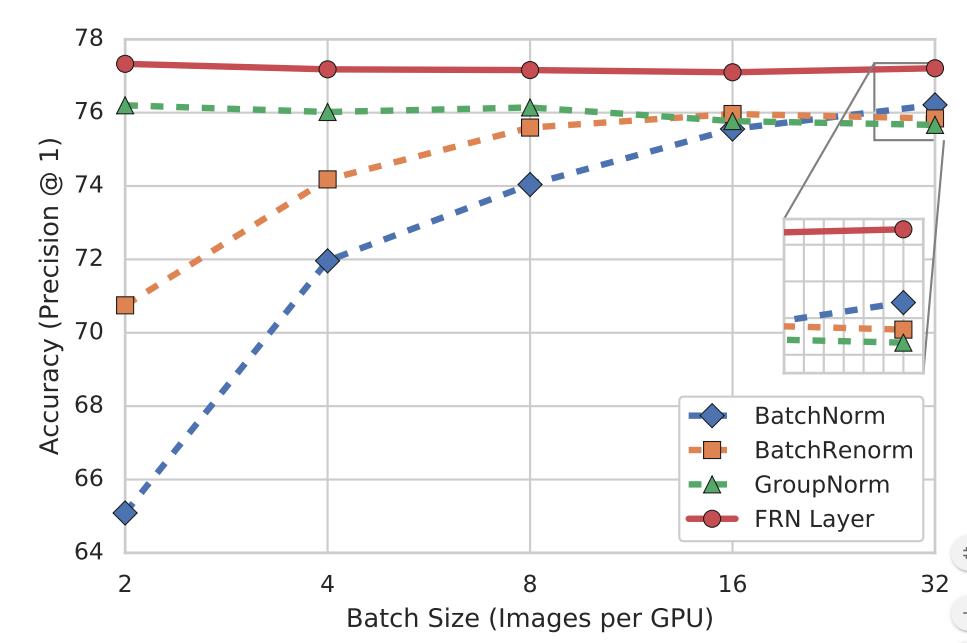
而且把BN+ReLU替换成BN+TLU, 也不会对性能有多少影响(基本没影响)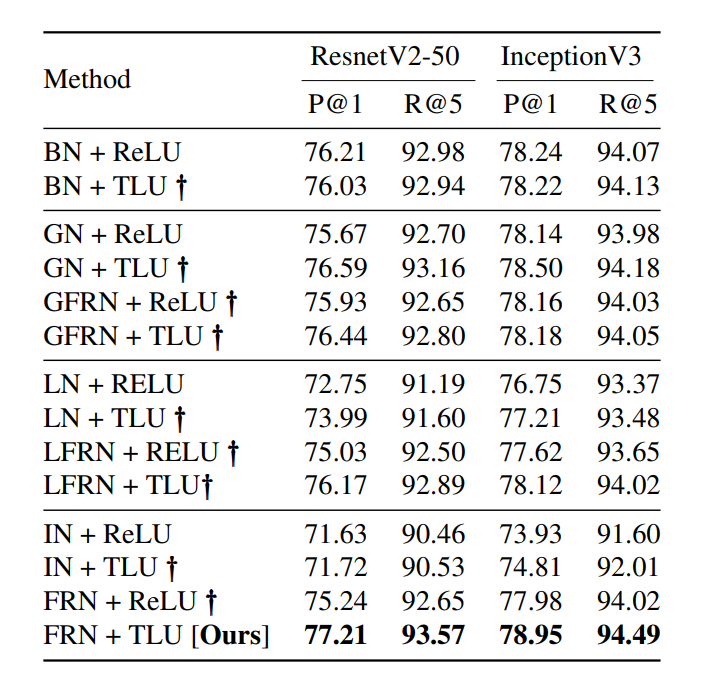
However
paper很美好, 但是自己玩了一下, FRN+Swish表现很好, FRN+TLU表现很一般…