
Abstract: In this paper, we explore the use of reference values (predictors) for the optimal objective function value of hard combinatorial optimization problems, instead of bounds, obtained by data mining techniques, and that may be used to assess the quality of heuristic solutions for the problem. With this purpose, we resort to the rectangular two-dimensional strip-packing problem (2D-SPP), which can be found in many industrial contexts. Mostly this problem is solved by heuristic methods, which provide good solutions. However, heuristic approaches do not guarantee optimality, and lower bounds are generally used to give information on the solution quality, in particular, the area lower bound. But this bound has a severe accuracy problem. Therefore, we propose a data mining-based framework capable of assessing the quality of heuristic solutions for the 2D-SPP. A regression model was fitted by comparing the strip height solutions obtained with the bottom-left-fill heuristic and 19 predictors provided by problem characteristics. Random forest was selected as the data mining technique with the best level of generalisation for the problem, and 30,000 problem instances were generated to represent different 2D-SPP variations found in real-world applications. Height predictions for new problem instances can be found in the regression model fitted. In the computational experimentation, we demonstrate that the data mining-based framework proposed is consistent, opening the doors for its application to finding predictions for other combinatorial optimisation problems, in particular, other cutting and packing problems. However, how to use a reference value instead of a bound, has still a large room for discussion and innovative ideas. Some directions for the use of reference values as a stopping criterion in search algorithms are also provided.
>>摘要: 在这篇文章里, 我们探讨了使用参考值(预测变量)来代替使用数据挖掘直接获得边界的方法去求解难组合优化问题的最佳目标函数, 并用来评估启发式求解的质量. 为此, 我们使用2D-SPP来研究这种方法, 这个问题在工业界很常见. 一般情况下, 2D-SPP通过启发式方法求解, 求解的效果也较为良好. 但是, 启发式方法不能保证最优解, 通常使用下限来提供求解质量的相关信息, 尤其是区域下限. 但是下界存在严重的精度问题. 因此, 我们提出了一个基于数据挖掘的框架, 该框架能够评估2D-SPP启发式求解的质量. 通过将得到的条带高度解与左下填充法和问题特征提供的19个预测因子进行比较, 拟合出回归模型. 随机森林作为较为泛用的数据挖掘模型被我们选用, 并生成了30,000个问题实例来表示在实际应用中发现的不同2D-SPP变体. 拟合的回归模型中可以找到关于新问题实例的高度预测. 实验表明, …(后面几句不看了)
亮点
- 这个数据挖掘框架可以评估启发式解的质量.
- 回归模型拟合了左下填充解和19个预测因子.
基于数据挖掘的框架(Data mining-based framework)
整个过程是这样的: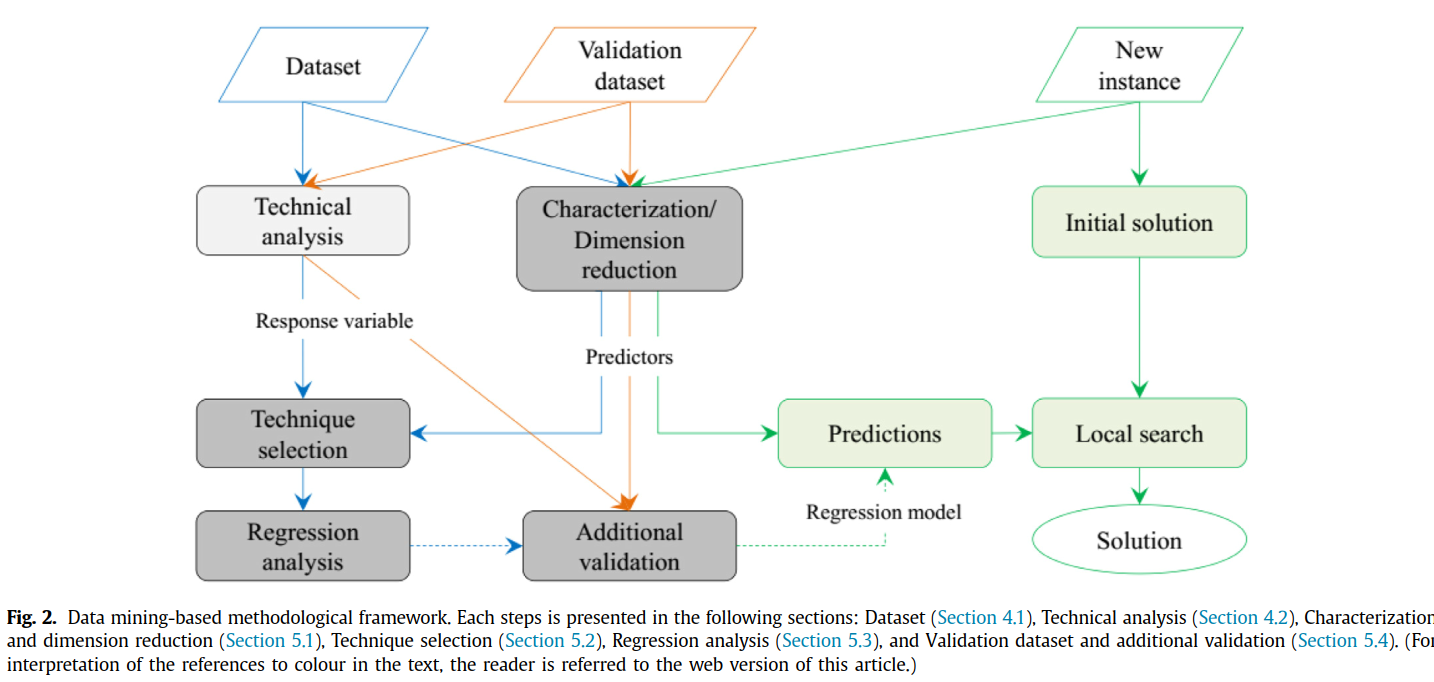
先从总体来看, 蓝色训练集, 橙色验证集, 绿色问题实例(等于测试集, 不过这里只能算测试实例), 通过对训练集拟合回归模型, 输出条带高度, 测试实例初始化一个解, 之后进行局部搜索并且用模型输出的条带高度作为其搜索的终止条件. 文章里说浅灰色块是knowlegde discovery(知识发现?)步骤, 深灰色是数据挖掘步骤.
文章中用了一大堆来介绍每个部分, 我就不说这么细了, 只讲几个主要的点.
数据生成的内容这里也不讨论.
Technical analysis
拿到一个训练集$X$(自己生成), 首先利用以往的2D-SPP技术进行求解, 得到解和下界(我对2D-SPP不是非常熟悉, 根据文章表述是这样的), 这里不讨论用的什么2D-SPP方法.
C/D reduction
总之, 根据这个结果, 得到反应变量(Response variable, R variable)的就是$Y$, 那么拥有$X$和$Y$, 自然也就能做回归了. 但是$X$肯定是不能直接输入的, 因此需要经过一个预处理, 在文章里, 经过处理后的$X$, 被称为预测子(Predictors), 当然, 这个预测子是经过降维的, 在文章给出的问题中得到19个预测子, 可以利用PCA之类的直接降维.
Technique selection
主要是对比各种数据挖掘模型, 选一个最合适的, 文章里最终使用的是随机森林. 方法是计算决定系数(或者判定系数, 拟合优度)$R^2$. 这里拓展的将一下$R^2$:
$R^2$反应了$y$的波动有多少百分比能被$x$的波动所描述, 即表征依变数$Y$的变异中有多少百分比,可由控制的自变数$X$来解释.
表达式: $R^2 = \frac {SSR}{SST} = 1 - \frac {SSE}{SST} = 1 - \frac {\sum_i (y_i - f_i)^2}{\sum (y_i - \hat y)^2}$
$y$是实际值, $\hat y$是平均值, $f$是预测值.
SST=SSR+SSE, SST(total sum of squares)为总平方和, 证明过程可以看看这里, SSR(regression sum of squares)为回归平方和, SSE(error sum of squares) 为残差平方和.
意义: $R^2$越大, 自变量对因变量的解释程度越高, 自变量引起的变动占总变动的百分比高. 观察点在回归直线附近越密集.
需要注意的是, $R^2$一般用在线性模型中, 并且不能反映模型预测能力的高低.
Regression analysis
这部分内容基本都在讲随机森林是如何工作在我们的问题中的, 事实上就是在讲随机森林这个算法.
Additional validation
利用RMSE做验证指标, 没什么好说的.
inference
由上述得到一个回归模型, OK, 接下来自然是如何推理.
一个新的问题实例到来, 首先仍然是预处理降维得到预测子, 由预测子输入到利用验证指标里得到的最佳模型推理出$g\hat a p_{ref}(L_0)$, 这个输出的变量定义为:
In our research, the gap $g\hat a p_{ref}(L_0)$ is the normalised value to be used as a known response variable in the regression analysis.
并且$\hat H^{ref} = L_0(1+gap^{ref}(L_0))$.
将它作为局部搜索的终止条件.
文章表明预测值和实际计算出来的值具有相当小的误差.