
AdaptIS: Adaptive Instance Selection Network
论文地址: https://arxiv.org/abs/1909.07829?context=cs
代码: https://github.com/saic-vul/adaptis
本文提出了自适应实例选择网络(Adaptive Instance Selection Network),给定图像和其中任意像素的坐标,AdaptIS即可精准输出这个像素处任意物体的mask。与目前流行的先检测后分割的方法不同,AdaptIS直接从像素点出发,达到对任意类别、任意形状物体的精准分割。 AdaptIS不使用COCO预训练即可在全景分割数据集Cityscapes和Mapillary上达到了state-of-the-art的效果,PQ(Panoptic Quality)指标分别为62.0和35.9,在COCO数据集上也有不错的效果。
>>
文章前面介绍了一些全景分割(Panoptic Segmentation)和一些相关工作, 那么这里直接进入正题.
Architecture overview

网络结构如上图所示, 以一个图像和一个点提议(point proposal)(x,y)作为输入和输出位于位置(x,y)的一个object的mask, 几个亮点:
- 利用AdaIN机制构建出实例选择网络.(把风格迁移的东西搬到分割来了)
- 利用控制器网络(controller network)为AdaIN层提供输入, 该输入包含提议点(x, y)位置的特征, 由一系列全连接层组成.
- 还有一个CoordConv块, 作用是帮助消除在不同位置上的相似目标的歧义(不难理解, 毕竟只输出提议点对象的mask嘛).
实例选择网络(instance selection network)
简单的说, 我们有一个向量(或者”特征”向量, 直接叫特征向量不太严谨, 该向量只是描述某个物体), 这个向量描述了某个物体, 利用这个向量可以把不同物体区分开来. 于是问题来了, 如何利用这个向量来生成mask呢? 作者的灵感来自于风格迁移领域的Adaptive Instance Normalization (AdaIN). 关于AdaIN是如何工作的, 可以去看一下相关的资料, 是一篇不太新的paper所以资料很多.
作者提出了一个轻量级的实例选择网络, 按作者的说法是该网络是被AdaIN参数化的(说白了就是用AdaIN调整过参数呗), 因此, “特征”向量包含实例选择层的主要参数, 利用backbone和”特征”向量提取的特征生成对象的mask.
于是问题就变成了如何提取好的向量.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21def _get_instance_maps(self, points, adaptive_input, controller_input):
self.num_points = points.size(1)
if getattr(self.controller, 'return_map', False):
w = self.EQF(controller_input, points)
else:
w = self.EQF(controller_input, points)
w = self.controller(w)
points = points.view(-1, 2)
x = adaptive_input.repeat_interleave(self.num_points, dim=0)
if self.with_coord_features:
x = self.add_coord_features(x, points)
x = self.block0(x)
x = self.adain(x, w)
x = self.block1(x)
if self.rescale_output:
scale, bias = self.rescale_output
x = scale * x + bias
return x
点提议和控制器网络(point proposal and controller network)
说到特征向量, 大家的第一反应往往都是嵌入空间, 相同对象的距离近, 不同对象距离远. 作者的嵌入思想有一些不同:
The output of a backbone Q may have lower spatial resolution compared to the input image. Thus, for each point (x,y) we obtain corresponding embedding Q(x,y) with the use of bilinear interpolation. The resulting embedding Q(x,y) is then processed in a controller network, that consists of a few fully connected layers. Controller network outputs a ”characteristic” vector, which is then passed to AdaIN layers in instance selection network. Using this mechanism the instance selection network adapts to the selected object.
由于主干输出的分辨率较低(经过卷积嘛), 因此对于每个点, 使用双线性插值来得到嵌入$Q(x, y)$, 并输入到控制器网络中, 经过几个全连接层(不过作者在代码里似乎用的是卷积层), 输出一个”特征”向量, 并传递给实例选择网络的AdaIN层.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class SimpleConvController(nn.Module):
def __init__(self, num_layers, in_channels, latent_channels,
kernel_size=1, activation='relu', norm_layer=nn.BatchNorm2d):
super(SimpleConvController, self).__init__()
# flag that indicates whether we use fully convolutional controller or not
self.return_map = True
# select activation function
_activation = ops.select_activation_function(activation)
controller = []
for i in range(num_layers):
controller.extend([
nn.Conv2d(in_channels, latent_channels, kernel_size),
_activation(),
norm_layer(latent_channels) if norm_layer is not None else nn.Identity()
])
self.controller = nn.Sequential(*controller)
def forward(self, x):
x = self.controller(x)
return x
没有直接优化嵌入之间的距离, 而是:
the controller network connects backbone and instance selection network in a feedback loop, thus enforcing backbone to produce rich features characterizing each particular object.
作者说这样做比使用辅助损失更好, 后面提到这是因为在网络会为属于同一个对象的点提议生成类似的输出, 相当于直接优化mask, 比使用优化嵌入距离作为.
关于Relative CoordConv, 其实就是一个坐标转换的过程, 把归一化到$[-1, 1]$的像素坐标加入到输入特征里.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21def _get_instance_maps(self, points, adaptive_input, controller_input):
self.num_points = points.size(1)
if getattr(self.controller, 'return_map', False):
w = self.EQF(controller_input, points)
else:
w = self.EQF(controller_input, points)
w = self.controller(w)
points = points.view(-1, 2)
x = adaptive_input.repeat_interleave(self.num_points, dim=0)
if self.with_coord_features:
x = self.add_coord_features(x, points)
x = self.block0(x)
x = self.adain(x, w)
x = self.block1(x)
if self.rescale_output:
scale, bias = self.rescale_output
x = scale * x + bias
return x
我们需要向网络提供对象的坐标, 但是不希望在backbone中使用坐标, 这是考虑到预训练所以不希望改变backbone的结构. 因此另外使用一个CoordConv块, 接在backbone的后面, 并依赖于点提议, 生成两个map, map的值被归一化到$[-1, 1]$, 代表了的是CoordConv的半径R内的坐标值, R是一个超参数, 大致代表了被检测对象的大小. 将其输出与backbone得到的feature一起输入到实例选择网络.
采样时对每个批次中的图像在对象级层面上取K个点. 随机选择一个对象, 并在该对象上随机取一个点. 采样到K个点后, 训练网络来预测K个mask, 为此, 作者对像素级损失函数做出一个调整, 调整后的损失函数可以比较网络的输入和GT Mask, paper里说最后使用了一种改进的焦点损失, 该损失具有最好的效果. 梯度后传至整个网络包括backbone.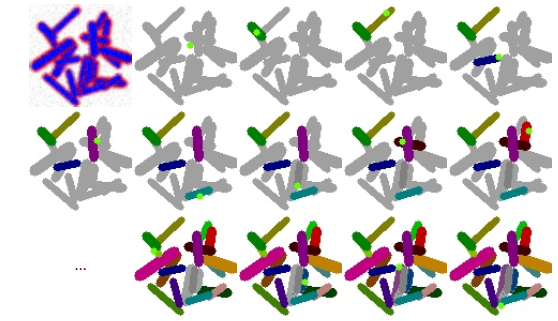
每次迭代的点提议都显示为浅绿色, 不同的实例用不同的颜色标记. 图像的“未知”区域显示为灰色. 在每次迭代中, 一个新的点提议被采样, 一个相应的实例被分割.
整个网络的内容差不多就这样, paper里还有更多内容, 包括实际在数据集上使用时是怎么样的, 已经实验结果, 这里就不写了. 在paper里展示的效果图在复杂情况下能准确地分割出对象, 看起来还是不错的.